Accelerating MoE Token Routing and Dispatch on GPU
Summary
Mixture of Experts models route each token to a small subset of expert networks at runtime. Before experts can compute, tokens must be packed into contiguous memory grouped by expert, an irregular scatter whose write pattern is entirely data dependent. On a single GPU, expert computation dominates runtime because each expert's FFN executes as a large matrix multiplication and the experts are processed largely in sequence. Expert Parallelism(EP) distribute different experts to multiple GPUs to parallelize computation across devices, but the packing step does not shrink with more GPUs, and AllToAll communication is added on top. As compute per device drops, packing and communication together become the new bottleneck. We plan to design and compare multiple parallel strategies for the packing and dispatch pipeline, analyze the scaling behavior from one to several GPUs, and characterize the tradeoffs between synchronization cost, memory bandwidth utilization, and communication overhead.
Background
Modern large language model inference has two phases: prefill, which processes the entire input prompt in one forward pass, and decode, which generates output tokens one at a time. We focus on prefill. During prefill, thousands of tokens pass through each layer simultaneously. In a Mixture of Experts layer, a small router network assigns each of the T tokens to K out of E total experts. Each token's d dimensional embedding must then be placed into a buffer where all tokens for the same expert are contiguous, so that expert FFN computation can proceed as efficient matrix multiplications.
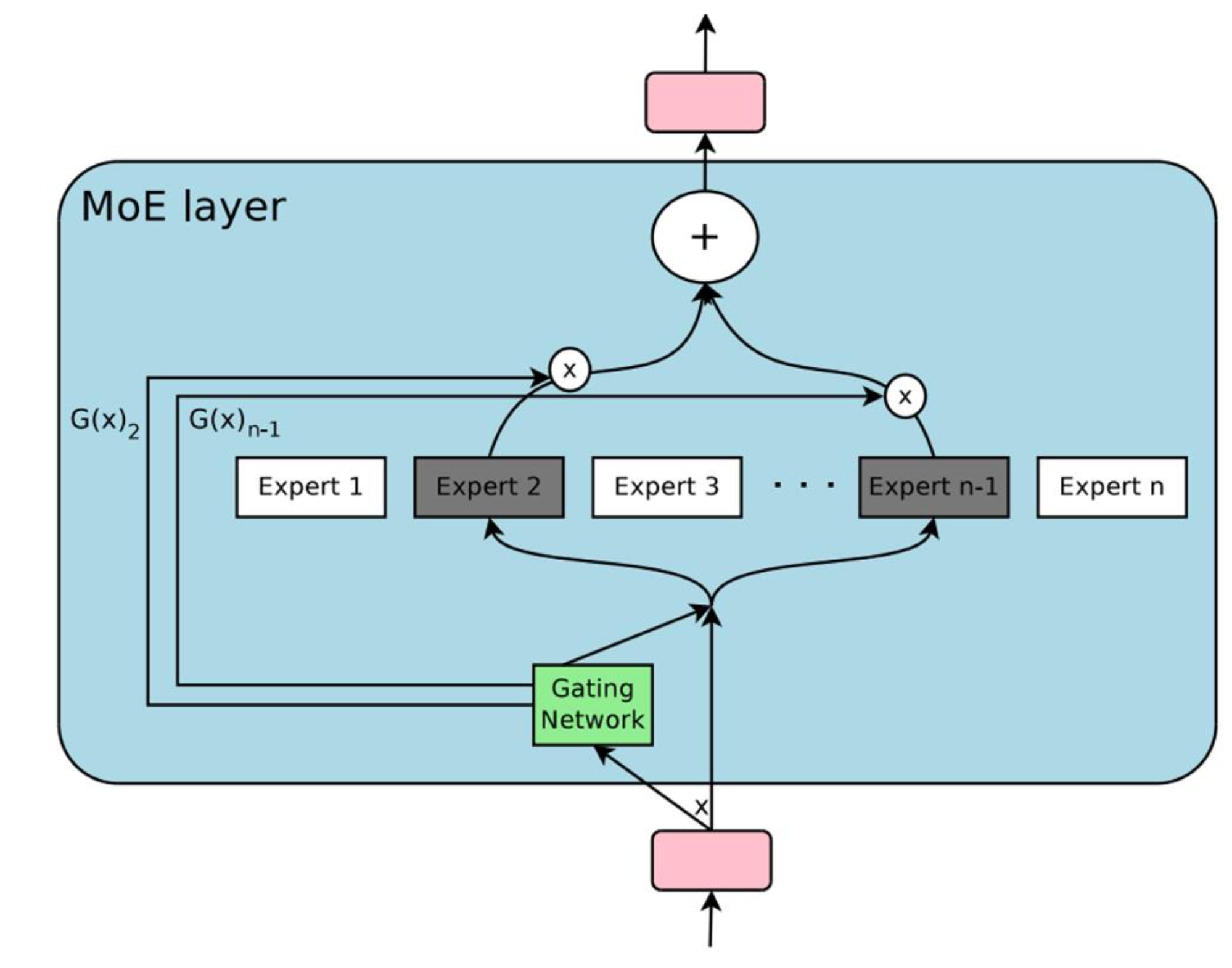
On a single GPU all experts reside in local memory. Expert computation dominates runtime: each expert's FFN is a large matrix multiplication, and because a single expert's GEMM is large enough to nearly saturate the GPU, the experts effectively execute in sequence. The packing step preceding computation is comparatively fast but still involves redundant data movement and unnecessary kernel launches in naive implementations.
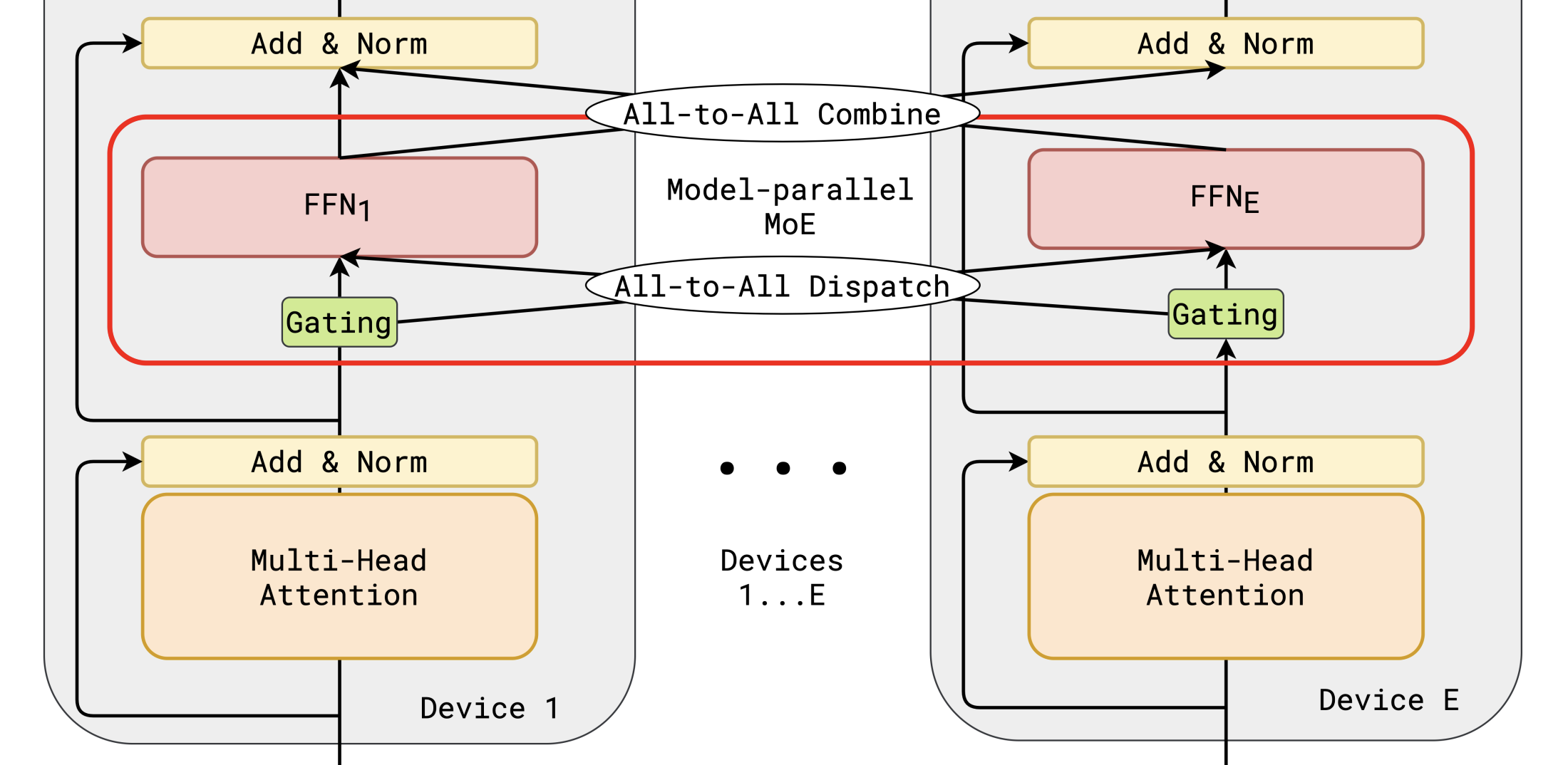
The picture changes when scaling to multiple GPUs. Each device holds a fraction of the experts and only computes its share, so per device compute drops proportionally. But the packing step does not shrink: every GPU must still pack all of its tokens regardless of how many devices participate. AllToAll communication is added on top, and its cost grows with both token count and the number of peers. As compute per device decreases, packing and communication together consume a growing share of total runtime. If communication is not overlapped with computation, the GPU sits idle during transfer and scaling falls well short of linear. This shift in the bottleneck from compute to packing and communication is the core motivation for our optimization work.
A sequential implementation of packing is trivial: iterate over all assignments, maintain a per expert write pointer, copy each embedding to the next slot. This is correct but entirely serial. We focus our effort on parallelizing this step and on overlapping communication with computation when scaling beyond a single device.
The Challenge
In dense Transformer models, the FFN processes all tokens through identical weight matrices, resulting in regular, coalesced memory access patterns that map naturally to GPU execution. MoE introduces a token packing step between routing and expert computation that breaks this regularity in several ways.
Write conflicts. When thousands of threads simultaneously pack tokens, multiple threads targeting the same expert compete for write positions in the same memory region. The conflict pattern is determined at runtime by the router and changes every forward pass. No static schedule can resolve these conflicts ahead of time.
Irregular memory access. After routing, adjacent threads in a warp typically target different experts, writing to distant memory regions. This destroys GPU memory coalescing. Sorting tokens by expert restores regularity but requires multiple passes over the full dataset, each involving a complete round trip through HBM. There is a fundamental tension between clean memory access and the cost of achieving it.
Load imbalance. Expert popularity depends on the input and is not perfectly uniform. Some experts receive substantially more tokens than others. Any parallel partitioning scheme must handle this runtime imbalance so that GPU resources are not left idle.
Communication scaling. When experts are distributed across GPUs, the AllToAll dispatch is an irregular collective where each GPU sends a different number of tokens to each peer, determined only at runtime. The GPU is completely idle during a synchronous AllToAll. Overlapping this communication with computation requires splitting work into chunks, managing dependencies between chunks with CUDA streams and events, and carefully balancing chunk sizes so that neither the compute nor the communication side starves.
Synchronization granularity tradeoff. There are fundamentally different ways to resolve write conflicts. Global sorting eliminates conflicts but requires multiple data passes. Per thread atomics are single pass but serialize under contention. Warp level coordination using SIMD intrinsics avoids both problems but requires shared memory orchestration and synchronization barriers. A fourth option is to skip packing entirely and perform scattered reads during expert computation, trading packing cost for irregular GEMM access. Each approach sits at a different point on the parallelism versus synchronization spectrum. The optimal choice depends on workload parameters such as the number of experts, tokens, and the skew of the routing distribution. Mapping this tradeoff space is the central goal of this project.
Resources
- Hardware: GHC cluster NVIDIA GPUs for single device work. PSC machines if multi GPU access is available.
- Software: CUDA C++, CUB library, cuBLAS. NVIDIA Nsight Compute and Nsight Systems for profiling.
- Starting point: All core kernel implementations will be written from scratch. We will study the following open source projects for design reference:
- ScatterMoE — scatter/gather approach that avoids explicit packing
- MegaBlocks — block sparse GEMM reformulation of expert computation
- DeepEP — high performance AllToAll kernels for expert parallelism
- SGLang / vLLM — production MoE routing kernels using sort based dispatch
- References: Shazeer et al., "Outrageously Large Neural Networks: The Sparsely Gated Mixture of Experts Layer," ICLR 2017. NVIDIA CUDA C++ Programming Guide.
Goals and Deliverables
- A sequential CPU baseline and a naive parallel GPU baseline for the token packing problem
- Multiple parallel packing strategies with fundamentally different approaches to conflict resolution, memory access, and synchronization
- Performance comparison across realistic MoE configurations varying the number of experts, tokens per batch, top K, and routing skew
- Microarchitectural profiling with Nsight Compute: HBM traffic, atomic contention, shared memory bank conflicts, achieved bandwidth versus roofline
- An end to end single GPU MoE layer benchmark covering routing, packing, and expert GEMM
- Analysis of when and why each parallel strategy wins, with quantitative explanation grounded in hardware characteristics
- Multi GPU scaling with AllToAll dispatch via NCCL, including pipeline overlap of packing, communication, and expert computation using CUDA streams
- Scaling analysis from 1 to 4 GPUs showing how communication overhead limits speedup and how pipelining recovers it
- CPU parallel implementation with OpenMP and SIMD for cross platform bottleneck comparison
- A fused single kernel that performs routing decisions and packing in one launch, eliminating all intermediate memory materialization
- Focus on two strategies instead of three or more
- Reduce the parameter sweep and drop the end to end layer benchmark in favor of isolated scatter kernel analysis
Platform Choice
NVIDIA GPU is the natural platform for this workload. MoE inference runs on GPU in production, and the token packing problem directly exercises GPU specific parallel challenges: warp level SIMD coordination, shared memory bank conflicts, memory coalescing sensitivity, and atomic contention under skewed access patterns. We use CUDA C++ rather than higher level frameworks like Triton because we need explicit control over shared memory layout, warp intrinsics, and synchronization primitives to implement and meaningfully compare our strategies. If multi GPU hardware is available, we will additionally use NCCL for AllToAll communication, which exercises a different axis of parallel systems design: overlapping network transfers with on device computation using asynchronous streams.
Schedule
Mar 25 to 30
Mar 31 to Apr 6
Apr 7 to 13
Apr 14 to 20
Apr 21 to 27